The Data Made Us Do It

There is no such thing as a "data-driven" decision
Recovering from winter-time illness, I am returning to form on this SubStack by just reacting to the latest thing that caught my ire on the internet, this time the article Men Have Abandoned Marriage and Parenthood from the blog Graphs about Religion.
I encountered this piece in Aaron Ren's excellent newsletter, and given that it touched on one of our mutual interests (the problem of relationship and family decline in the 21st century) I read the whole thing in detail despite Ren's disclaimer concerning its "blue-pilled assumptions”. But "blue-pilled assumptions” only scratch the surface, since the analysis contains huge problems in its methods, less numerical than in its philosophical approach to tackling hard problems with data.
The author, Ryan Burge, seems like a nice guy. While I don't want to completely trash the man’s work, I have to say that the article is a perfect picture of statistically backward thinking. It's not just that the assumptions behind the model are "blue-pilled", the entire approach falls into a pattern I have been observing for some time in how journalists and laypeople talk about data analysis, especially in the wake of Large Language Models (LLM) and "A.I.".
In broad strokes, Mr. Burge attempts (like many before him) to isolate the cause of family decline in the post-2012 world. To do this he imports a large cross-sectional matrix from the Cooperative Election Study on Marriage, isolates a single label, “never been married”, and takes broad hacks across the set longitudinally, adjusting for several key factors.
As someone who works with data professionally, Burge's process looks silly, not least because the author takes a highly developed question and then digs into a new analysis as if no prior knowledge or work existed on the subject. It's already a ham-fisted approach, so it comes as no surprise to see Mr. Burge divide his cohort into men and women (broken out by ethnicity, religion, education, and income), observe a gap between the sexes, and then breathlessly arrive at the conclusion that, "men are the real problems here".
Does that not sound right to you? Perhaps it doesn't match up with your "lived experience"? Maybe it sounds like it plays right into the “woke” narrative? Is the question even well-posed? After all, what does "men are the problem" even mean?
These are hard questions. But don't put them to Mr. Burge, he didn't come to these conclusions. This was just the answer that the data provided him.
And so confident is the author in the oracular power of "the data" that, despite the very limited trends demonstrated, Mr. Burge strengthens his conclusions as the article progresses, eventually asserting that the broad trends in family decline are caused by "men walking away". It's not until the final paragraphs that Mr. Burge realizes he is out over his analytical skis and retreats back to the typical refrain that "more research is needed".
So in conclusion we have "men are at fault, more research needed"?
Really, could you find a better preliminary conclusion for a successful progressive grant proposal in just seven words? Entire academic careers have been built just on repeating this conclusion over and over again. And, if you could find a way to sell these results as "data-driven", you would be made for life in a modern University.
As readers might suspect, there are a lot of mistakes going on in Mr. Burges's analysis. Most fundamentally, the author is treating his dataset like it fell out of the sky. He doesn't know what a man is. He doesn't know what a woman is. He doesn't know what marriage is. All of these data points are just numbers describing widgets from planet Zongo. And, if there are more bad effects associated with the "male" widgets, that means that those "male" widgets caused the bad effects of their own volition.
The core of Mr. Burges's article comes down to just one graph, re-hashed several times with adjustments, that shows a gap (suspiciously closed at each end) in the "has ever been married" measurement between men and women with women having married more. From this graph, supposedly, we can discern evidence of a mass defection of the institution driven by men shirking their responsibilities.
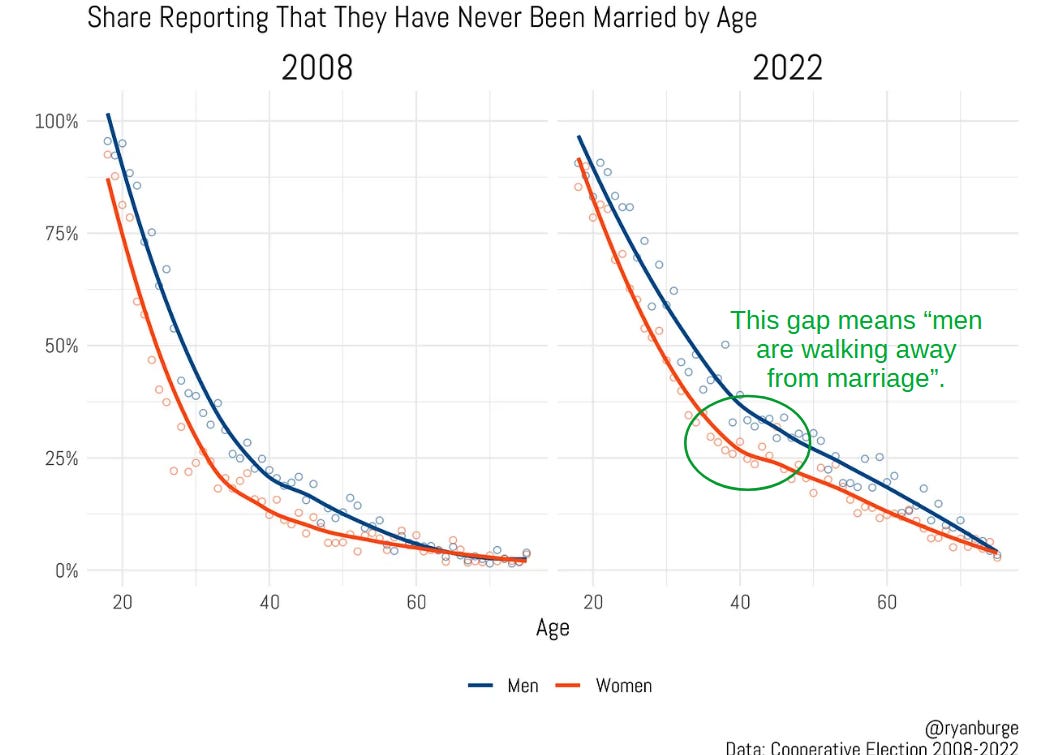
But Mr. Burge's conclusions can't hold up to even a few moments of introspection. For instance, when I taught statistics I used to tell my students to sanity check their results by looking at their graph, pointing to a position on it, and asking themselves"What is going on here in real life?". What would such a method reveal about Mr. Burge’s data set? After all, his data describes something that we all understand from life: real men, real women, and real relationships.
Quite obviously, on examining the family-formation question this way we would immediately realize that marriage is not an individual question but a pair-matching problem. Given that polygamy and gay marriage are still statistically rare in America at the time of the sample, virtually every marriage is a match between both a man and a woman, meaning that any sex difference that appears statistically in the "has ever been married" category must be the result of one of two effects:
- Women marrying men from outside the cohort, or
- Women marrying and divorcing, with their ex-husbands remarrying never-before-married women.
In either case, neither effect originates from the decisions of men who have never been married and could not provide evidence of a mass shirking of marriage by single men.
More to the point, if marriage did work as Mr. Burge implies and its incidence was simply a matter of each party individually “wanting it more”, we could just as easily "derive from the data" the idea that "women are the problem”. Case in point, a recent Pew Survey showed that young women are the more reluctant parties when it comes to future family formation.
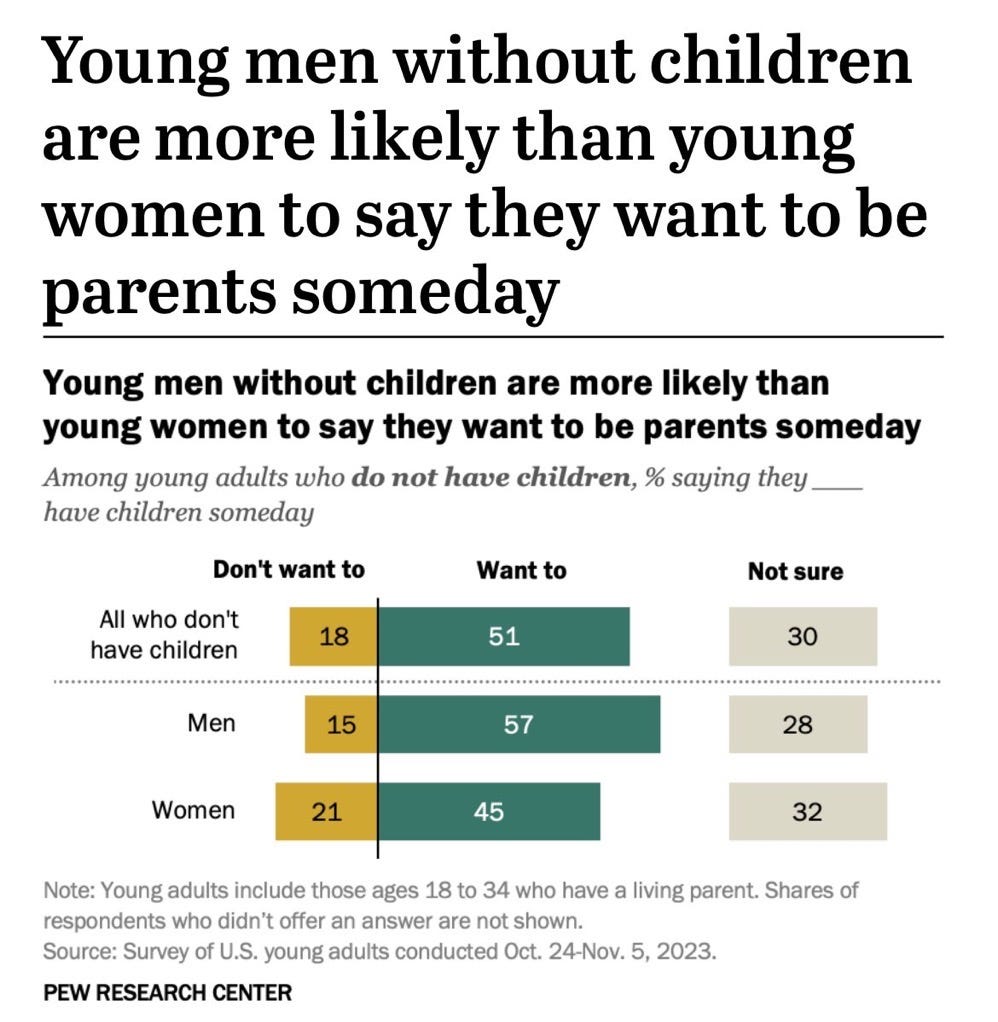
Nevertheless, the alternative conclusion that “women are the problem” would be equally silly.
Neither men nor women can collectively "be the problem" in a market-matching game, at least in the way that Mr. Burge is implying in his article. There could be a problem with how each side of the gender divide values marriages, there could be a problem with how each sex has set their standards for accepting mates, and that problem may be lop-sided between the sexes. But you could never, even theoretically, derive this kind of conclusion from a data set describing just the incident of marriage, because (sort of an explosion of bigamy or homosexuality) it takes two to tango.
And Mr. Burge’s conclusion is made all the more strange by the fact that, in his haste to chase the ghost of male culpability, the author blows off the most notable element of his data set. Pointing out, and then sidestepping, the conclusion that increased education makes men more likely to get married, but has a neutral or negative effect on women’s prospects for matrimony.
This last conclusion won't be surprising for anyone who has explored the topic in more depth. And for those interested, I would certainly recommend Aporia's in-depth investigation into the ultimate causes of the baby bust.
However, this is not the point that I want to explore in this essay.
The problem I see in the previous analysis is less a particular mistake interpreting data and more an underlying philosophical misunderstanding. In 2024, very few people have a good appreciation of what data models actually are. Subsequently, we just see cargo cult statistics with people imitating the form of the process (e.g. collecting data sets, generating R-values, making graphs) with no understanding of the purpose or limitations of the endeavor. People demand "data-driven" analysis but then just extract measurements and graphs from data sets and project their conclusions on them like oracles hovering over tea leaves. No greater criticism about the context or framing of the question is performed.
It would be one thing to see this attitude isolated on some statistics blogs, but in the era of “A.I.” and machine learning this error has captured our entire society. What went wrong?
We need to start with a hard reality.
There is no such thing as a data-driven decision.
I know this goes against everything we are supposed to believe in our modern information age. And perhaps a reader might be surprised to hear this from me, considering I am fond of reminding people that “the data is real, and the model is just a guess”. But difficulties in complex analytics aside, one cannot simply fall back on pure observation, treating the data as a magic object, and looking for some kind of answer to spring forward from its form like Athena from the head of Zeus.
![Attic black-figure exaleiptron of the birth of Athena from the head of Zeus (c. 570–560 BC) by the C Painter[208]](https://substackcdn.com/image/fetch/w_1456,c_limit,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fb2f940f2-f0f1-4461-ae96-7d2da960a03e_860x773.jpeg "Attic black-figure exaleiptron of the birth of Athena from the head of Zeus (c. 570–560 BC) by the C Painter[208]")
I know that a large number of my readers consider the subject of data analytics boring. But de-mystifying this practice is important, especially in 2024, when our ruling class is divided between process-obsessed legal autists, data-obsessed technical autists, and the Large Language Models built from their cooperation.
More often than not, whether it is machine learning, data mining, "Artificial Intelligence", or even the conclusions of statistics blogs, data analytics are performed like a magic trick. A shiny truth is dangled in front of the readers’ eyes while the magician smuggles deception after deception out of this linguistic hat.
I think we need some more reflection on exactly how these tricks are done.
At its core, data analysis is simply the process of translating a set of highly formalized "observations", that we call data, into some expression in human language that we consider "true" or "useful". And, at a broad scale, analytics can be reduced to just three components:
- The Model,
- The Data,
- The Frame.
Briefly, I can explain each.
First, and the one that you hear the most about, is the model, the engine of the analysis. A data model is usually expressed formally with mathematics and driven by computation (usually via a Turing machine). This includes pretty much everything that we ordinarily consider software from regression analysis, the code running on your Excel spreadsheet, or the Large Language Models (LLM) incorporated in Google or Microsoft's latest "A.I." projects. The form is always the same, observations and data go in, and some programmed output comes out, trained by the model assumptions to represent something about reality suited to the user's demands.
Second, and more importantly, there is the data. Data is some historical record that an analyst considers a proxy for reality, by assumption. Most commonly this includes large matrices of labeled data and associated descriptive database entries. However, more generally, the data category would also include the input parameters, rules, and heuristics that are fed into any given model.
Third, there is the frame, sometimes called "business requirements" in industry. The frame defines the purpose, truth, and validity of any combination of modeling and data. Not only does the frame impose arbitration on the results, it defines every axiom that is fed into the previous two components. What defines an effective model? What constitutes "good" logic? How do we deem that the data is “true”? What are the assumptions we are bringing into these observations implicitly? What will make a model's answer useful? Each of these questions must have answers, explicitly or implicitly, to provide the foundation for an analysis.
To de-mystify the practice of data models, it’s important to understand that it's all just these components; nothing more and nothing less.
Another important thing to understand is that the importance of these components varies inversely with how often we ordinarily discuss them.
We talk constantly about algorithms, machine learning tools, computational frameworks, and LLMs. Still, as everyone in the industry knows, the data is where the real power of an analysis lies. The simplest algorithms can often infer good findings from an accurate and clear data set, while even the most complex models with the largest number of computational cycles suffer from the "garbage in garbage out" problem. Furthermore, almost no one talks about a model’s frame even though that frame controls everything the model generates and determines whether a project will be considered successful or not.
This last observation might be hard for laypeople to appreciate because the frame neither contains the observations nor the computations of the analysis. The frame doesn't involve any state-of-the-art technology. There are no lines of code, neural network parameters, or GPUs. Nevertheless, at the end of the day, the frame will determine the quality of the answers that a system will generate.
Even subtle variations on the type of question can lead to massively different results. Subsequently, without a way of understanding the purpose of the question at a moral and intuitive level, no meaningful decision can be made.
A classic example might illustrate this point.
Sometime in the mid-1970s, a study was performed at UC Berkeley showing that women were significantly less likely to be admitted into the school’s graduate departments, even though men and women applicants had roughly comparable resumes.
Was this a clear analysis of unfairness against women? Perhaps.
However, after further analysis, when admission rates were examined at the department level, the exact opposite conclusion was reached. For each department, across the board, women's admission rates were identical or even higher than their male counterparts.
So, based on the same data set, women were being under-admitted at the university level but over-admitted in each department that made up the University. How did this make any sense?
What the researchers had stumbled upon was a frustrating obstacle in translating statistics into human language, specifically Simpson's Paradox, where an effect can appear strongly in aggregate but then completely disappear in all sub-divisions.

In the Berkeley case study, what happened was a mismatch in the department admission standards inside the University where supply and demand of degrees and funding varied radically. Men disproportionally applied to the departments with higher funding and graduate admission rates (e.g. engineering). Women disproportionally applied to departments with lower funding and fewer, highly contested, graduate positions (e.g. humanities). Under these circumstances, there was necessarily a larger number of female rejections, even when the individual departments preferred female applicants.
So the statistical mystery is solved. But how do these statistical measurements help us answer the original question of whether anything “unfair” was going on in women’s graduate admissions? All the analysis has given us is two measurements, one microcosmic and one macrocosmic, each implying opposite conclusions. Which is the relevant quantity? Which is the signal and which is the noise?
There is no formal or procedural way to answer this question "from the data". It all depends on the frame we are using for the question.
With a normal understanding of how graduate admissions work, and a classic Western understanding of "fairness", the department-level measurement is the relevant statistic. Students are admitted via the individual department standards, so the lack of under-admission in each department would indicate no discrimination against females in the adjudication process. However, this conclusion is dependent on the moral assumption that fairness means a neutral standard of arbitration. From the perspective of equity, "restorative justice", or crude feminism, a neutral standard would likely be irrelevant next to the existence of disparate outcomes or the emotional trauma suffered by women due to their greater rates of rejection. The frame, not the data decides the issue.
There is no such thing as intelligence without contextual experience, moral teleology, and dynamic intuition. These qualities are injected into any data model via its frame, and constitute whatever real intelligence the analysis provides. As such, the process of using data to come to good conclusions is, at its base, experiential, intuitive, and difficult (perhaps impossible) to express formally.
Ultimately, I believe this informal quality of intelligence to be the core reason that A.I. alignment is almost certainly impossible in concept. A.I. alignment, or the theoretical field of constraining future Artificial Intelligence with rules that limit its possible actions, suffers from a major technical hurdle insofar as it tries to constrain the infinite future potential of a system totally unlike anything we've ever seen behind a finite set of formal rules. This endeavor appears reminiscent of the perennial human folly of trying to contain the infinite in the finite. And, although I certainly don't have a proof, I suspect that the A.I. alignment problem is directly analogous in its futility to the failed attempts at describing mathematical completeness or solving Turing’s “halting problem”.
However, at a more philosophical level, the A.I. alignment project embodies the same mistakes as Carlyle's "government by steam". Organic systems cannot simply be scooped out of their context and replaced by a formal set of rules while still maintaining their ability to be lifelike. As Ian Malcom from Jurassic Park might put it, either the artificial life in question breaks free of its constraints and becomes actual life, or it is eventually stifled and killed by its confining rules.
But this discussion about actual Artificial Intelligence is completely hypothetical in our own time because everything we see now is still just a variation of standard data analysis with whatever intelligence it demonstrates introduced to it externally, via its frame.
Moreover, to the extent that we mystify this technology, treating Large Language Models like Silicon humans, or worse, Silicon gods, humanity is setting itself up for a disaster.
I am hoping that a certain amount of de-mystification may have occurred recently in the wake of a series of LLM fiascos, most prominently Google's Gemini image creator which, despite repeated requests to create images of European historical figures and citizens from predominantly European countries,
just

could

not

draw

white people.

What could cause an advanced LLM to do this? Was there some bug in the code?
But it gets worse, Whatever assumptions about race, equity, and inclusion Google used to build their model also made the resulting text responses very open to genocidal sentiments, just as long as it was directed against the right (white) people.
Google was ultimately forced to take notice of the problem when people requested pictures of mid-century Germans and the predictable images of black SS Officers Gemini produced were deemed offensive to the African American community. Perhaps the engineers need to adjust some parameters? Maybe Google needs to recalibrate its model on more historical data?
But really, this fiasco should trigger a larger conversation as we contemplate the reality that Google tried to design an LLM with ungodly amounts of computational power to accurately and humanely represent history but instead produced a machine that couldn't do anything BUT create false, bigoted, and eliminationist portraits of the past.
And everyone watching this disaster unfold knows full well that these insane responses coming out of Google Gemini didn't spring spontaneously from a GPU cycle or coincidentally emerge from a misaligned neural network parameter. They were intentionally built into the system's framework by a management team who intended for Gemini to act less as a tool to represent history than as a weapon to systemically misinform its customer base and push Google's preferred political agenda.
Hey, remember when Google's slogan was "Don't be Evil"? What happened to that?
It sounds similar to another slogan from IBM in the 1970s:
"A computer can never be held accountable, therefore a computer must never make a management decision."

Just like the "Don't be Evil" idea Google floated in its early days, this notion about the impossibility of artificial accountability contains an acute wisdom that modern society is doing everything in its power to forget. Why does this so frequently happen? Well, it's simple. Responsible use of technology isn't profitable.
Initially, Google's "Don't Be Evil" slogan was an indirect reference to the founders' early intention not to sell or curate search results with promotional considerations, a practice that the creators felt would "bias" the information delivered by their search engine. However, as the company grew, and the Internet became the portal for all advertising and attention, Google's leadership realized that to become the biggest thing online, it needed to monopolize and sell attention. So the change was made, the slogan was dropped, and now Google curates most information online, selling ads to the eyeballs it controls.
There is a similar story behind most other technologies of our era. Video games aren't really doing their job unless they are addictive life-destroying time sinks. Social media isn't worthwhile unless it can replace real relationships and apply social control to its user base. Dating apps aren't profitable unless their users remain single and on the dating market.
I think we are in the process of discovering something very similar about this new "A.I." technology. It will only be truly profitable if it can sell itself as something it is not: accountable. However, once the fakery and magic are stripped away, it is just another computer model clinging to the data and parameters given to it by its creators. And people will only be impressed if they can envision the LLM like some masterful Artificial being, issuing authoritative truth in the name of "SCIENCE" born from incalculable processing power, data, and energy. Just ignore the little men behind the curtains pulling the levels and making the apparatus work.

But that's the trick, isn't it? Understanding that machine learning doesn't actually replace human thought spoils the magic because that would mean that human considerations have to be taken into account. That would mean that mankind's problems can't be solved with better algorithms running on ever-faster GPUs. That would mean that science and technology aren't the answers to every problem and that the government cannot be “run by steam”.
But these conclusions would require actual accountability, and no one wants that.
So expect to see more stale political platitudes recycled through LLMs, all giving variations of the response we heard earlier.
"Men are the problem!”
“White people are the problem!”
“Humans are the problem!”
“More A.I. research is needed!"
And also expect to hear the usual excuses from management that this is "just what the data told them to say". Despite what we hear from “A.I. optimists” about machines gaining sentience, neither the algorithms nor their creators will ever gain accountability. There is no profit in it.

Recently my wife asked me if I thought "A.I." was demonic. Perhaps not the strangest question, but I had difficulty giving her a good answer. To a degree, the consideration is more than a little silly since I have been urging throughout this article that "A.I.", as we know it, is simply an empty vessel. It only contains what we put into it.
But does this understanding answer the question about A.I.’s diabolical nature?
For years, even as a convert, I scoffed at the Catholic pretension that Ouija boards were a portal for demonic influence. After all, spiritual complaints directed at an object that I had known throughout my life as a board game seemed silly, echoing 80s paranoia about Dungeons & Dragons. But experience gradually taught me to be more cautious about the things that lie in those empty spaces when humans reach for spiritual forces they do not fully understand.
You put your hands down on the board, feed it meaningless impulses, and receive an answer. Are you communing with dark spirits? Or is the board just reflecting what you put in? Does it even matter?
After all, I don't know any greater darkness than the vicious self-terminating thoughts that circulate in the human mind once it is divorced of purpose and spiritual center. And if wresting these dark subconscious feelings from the mind, putting them on a pedestal, and then divesting them of any accountability cannot rightfully be called “demonic” then nothing can.
But this fiendish end is exactly what our society has elected to pursue, if not through the veil of sorcery then through the veil of self-deceptive technology. What first began as a perverse business model and twisted political ideology thus re-emerges as a demonic death cult, with each bad decision magnified as it is put on the alter of computational power.
But shouldn’t we have expected this? Modernity put man's soul in a box, removed his judgment, and sold this religion for any false promise sufficiently self-flattering. Are we really surprised now when the horned adversary steps forward to claim his due?
Nothing good can come from these developments. While science may never invent a species-destroying A.I. basilisk, the machine-learning revolution will likely succeed in accelerating our regularly scheduled civilizational decline by transferring the collapsing trust in experts to a collapsing trust in technology itself.
Then when the bad decisions built into this system overflow, when our society burns, and everyone stumbles out of their illusions of progress, those who come after will find it difficult to know who to blame.
One might point a finger at the men who set the machine in motion, the leaders who ignored wisdom in favor of expedience. One might even ask them why they decided to hand over humanity’s future to an endeavor so transparently foolish.
But I already know what their answer will be.
"The Data made us do it."